1Pattern Recognition Lab, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany, 2Magnetic Resonance, Siemens Healthcare, Erlangen, Germany
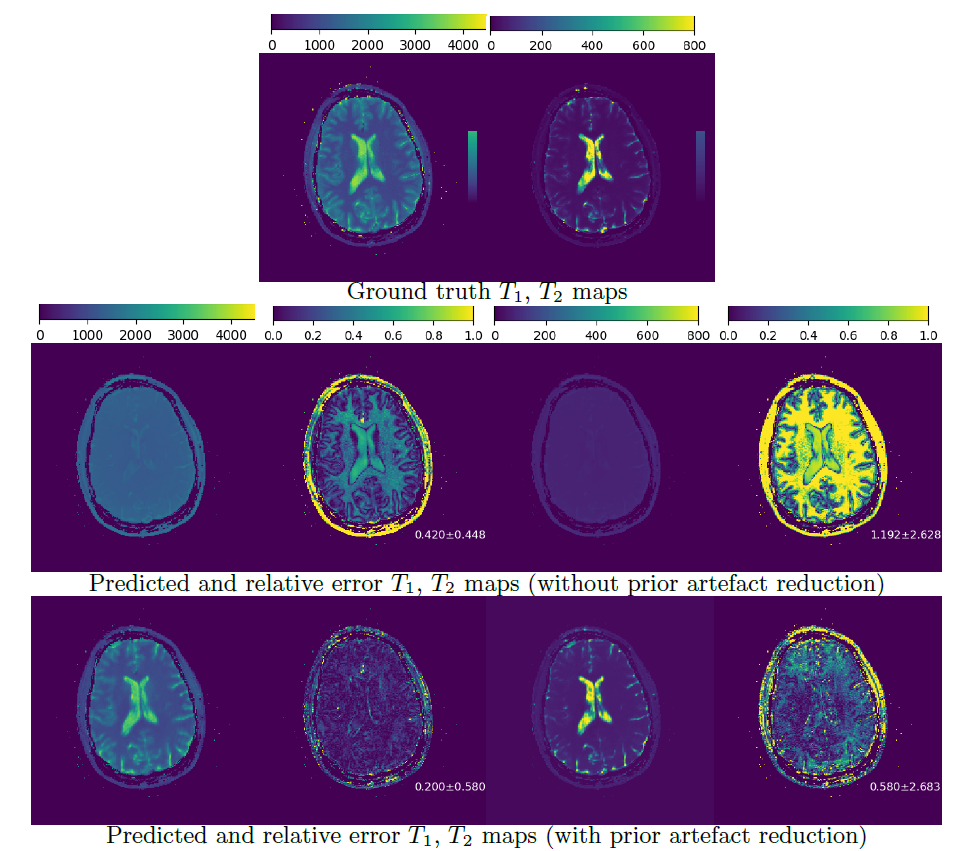
Figure 3: Quantitative maps from test scan
Row 1: Ground truth maps Row 2: Reconstructed maps without prior artefact reduction and relative error maps Row 3: Reconstructed maps from cleaned fingerprints and relative error maps A clear improvement in the reconstruction quality can be observed using a prior DL-based artefact reduction approach.
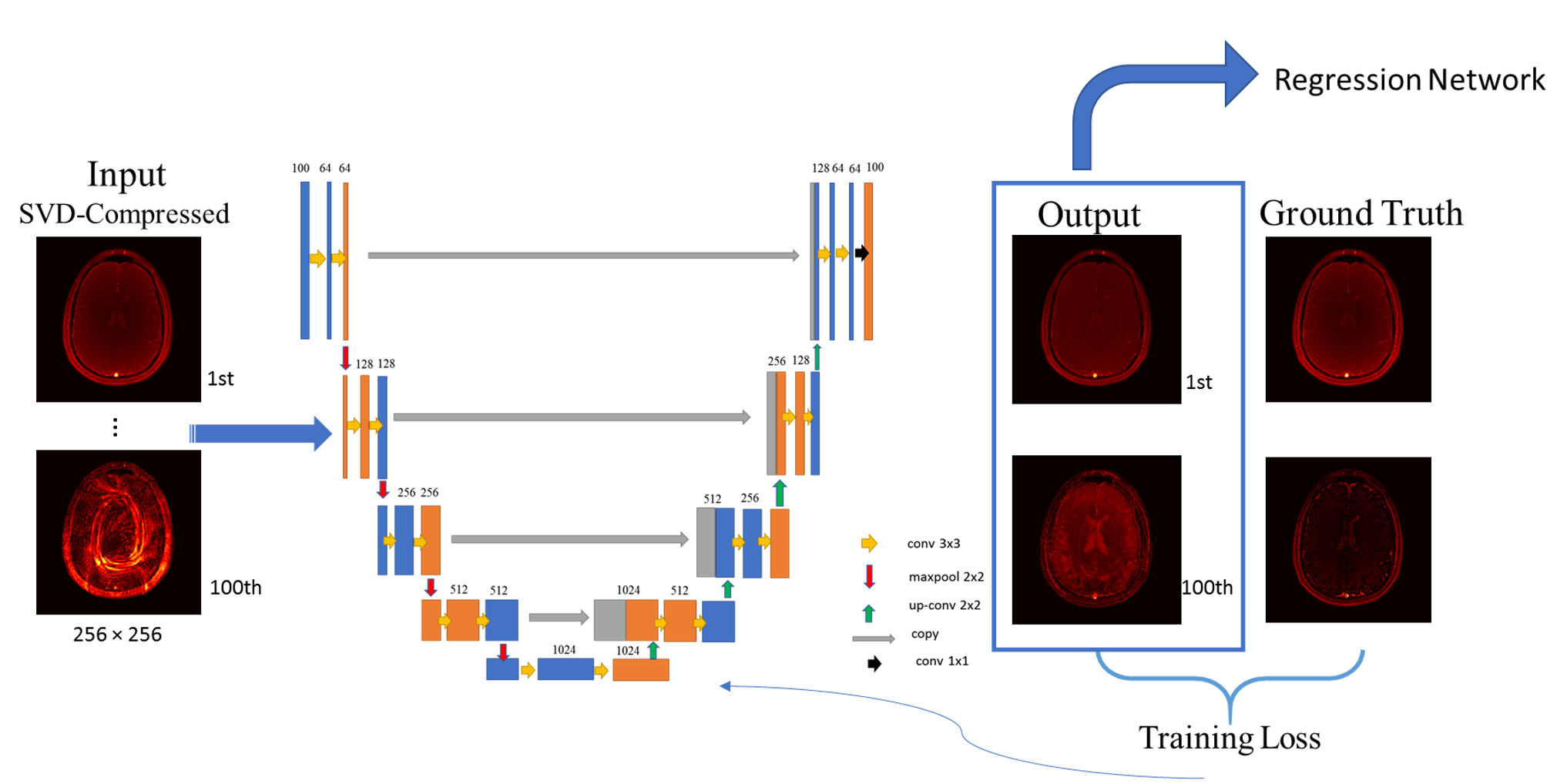
Figure 1: U-net architecture for the artefact reduction
As input for our U-net-based artefact reduction we use the main 50 complex-valued components of SVD-compressed fingerprints for each slice, resulting in 100 input channels for real and imaginary parts. The network outputs are the cleaned fingerprints of the same size as the input. For the training, the Mean-Squared-Error of the compressed signals from the dictionary matches and the network outputs is used.
