Chompunuch Sarasaen1,2, Soumick Chatterjee1,3,4, Fatima Saad2, Mario Breitkopf1, Andreas Nürnberger4,5,6, and Oliver Speck1,5,6,7
1Biomedical Magnetic Resonance, Otto von Guericke University, Magdeburg, Germany, 2Institute for Medical Engineering, Otto von Guericke University, Magdeburg, Germany, 3Data and Knowledge Engineering Group, Otto von Guericke University, Magdeburg, Germany, 4Faculty of Computer Science, Otto von Guericke University, Magdeburg, Germany, 5Center for Behavioral Brain Sciences, Magdeburg, Germany, 6German Center for Neurodegenerative Disease, Magdeburg, Germany, 7Leibniz Institute for Neurobiology, Magdeburg, Germany
1Biomedical Magnetic Resonance, Otto von Guericke University, Magdeburg, Germany, 2Institute for Medical Engineering, Otto von Guericke University, Magdeburg, Germany, 3Data and Knowledge Engineering Group, Otto von Guericke University, Magdeburg, Germany, 4Faculty of Computer Science, Otto von Guericke University, Magdeburg, Germany, 5Center for Behavioral Brain Sciences, Magdeburg, Germany, 6German Center for Neurodegenerative Disease, Magdeburg, Germany, 7Leibniz Institute for Neurobiology, Magdeburg, Germany
It has been shown here that super-resolution can be
improved using fine-tuning with one prior scan. After fine-tuning, the average
SSIM of all resultant time points were 0.994±0.003 for undersampled 25% and
0.984±0.006 for undersampled 10%.
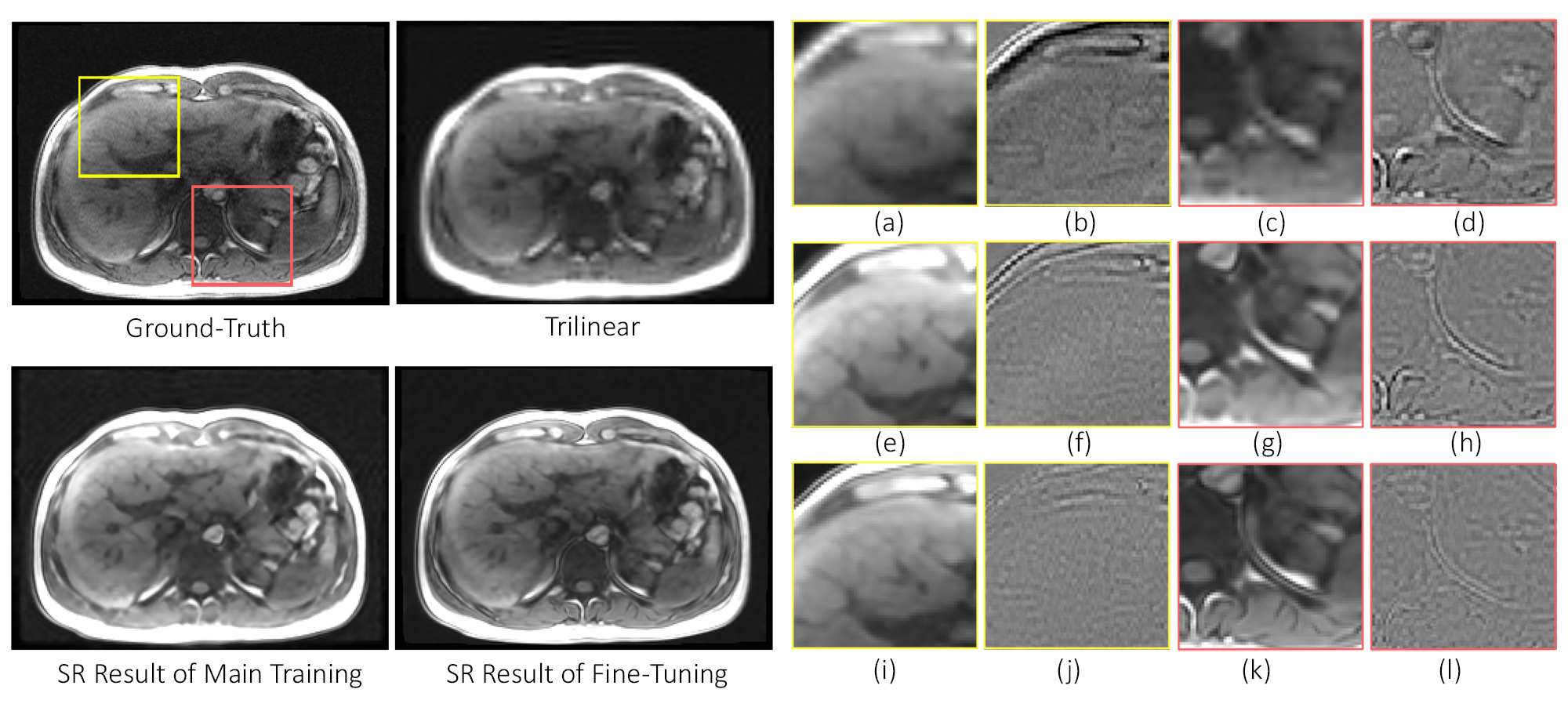
Fig.
3 The reconstructed results compared against its ground- truth for undersampled 10%. From left to
right, upper to lower: ground-truth, trilinear, SR result of main training and
SR result of fine-tuning. For the yellow ROI, (a-b): trilinear and the difference image, (e-f): SR result of the main training and the difference image and (i-j): SR result of after fine-tuning and the difference image. For
the red ROI, (c-d): trilinear and the difference image, (g-h): SR result of the
main training and the difference image and (k-l): SR result of after
fine-tuning and the difference image.
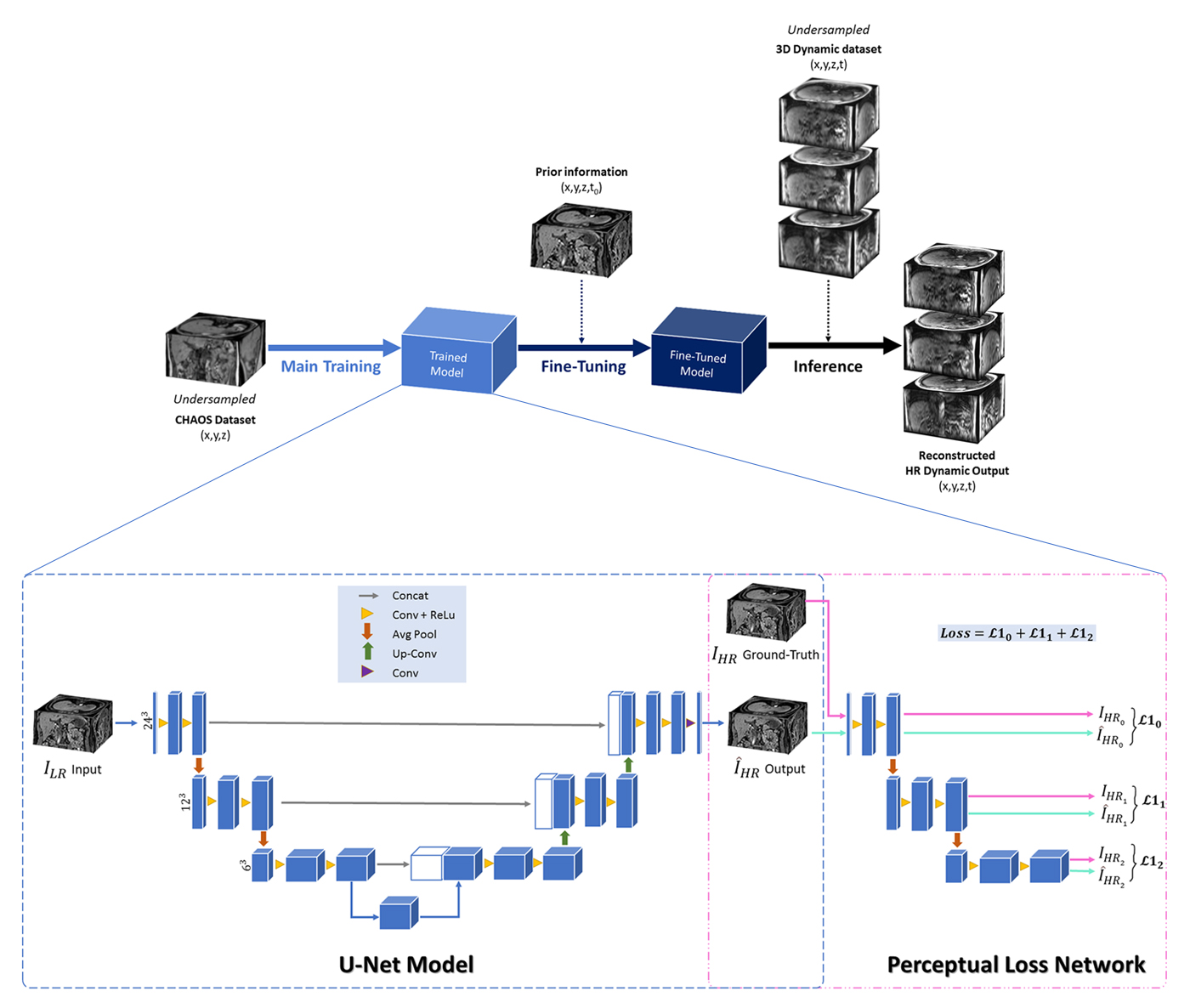
Fig. 1 The schematic diagram along with
network architecture in this work. A model is based on U-net with perceptual loss
was used for main training. The trained network was fine-tuned using prior scan
as a planning scan to obtain high resolution dynamic images during the
inference stage. The loss during training and fine-tuning were calculated with
the perceptual loss. The output loss at each level of a pre-trained perceptual
loss network was calculated using L1 loss.
