Prakash Kumar1, Yongwan Lim1, and Krishna Nayak1
1Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States
1Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States
Frame-by-frame super resolution using deep learning can be applied to speech RT-MRI across many scale factors. Quantitative improvements in MSE, PSNR, and SSIM were 38%, 8.9%, and 2.75%, respectively, compared to conventional sinc-interpolation.
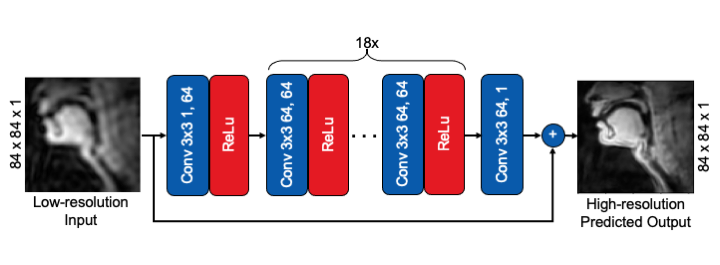
Figure 2: Network Architecture. The VDSR residual network consists of repeated cascades of convolutional (conv) and ReLU layers. The sum of the residual and the low-resolution input creates the high-resolution output estimated images
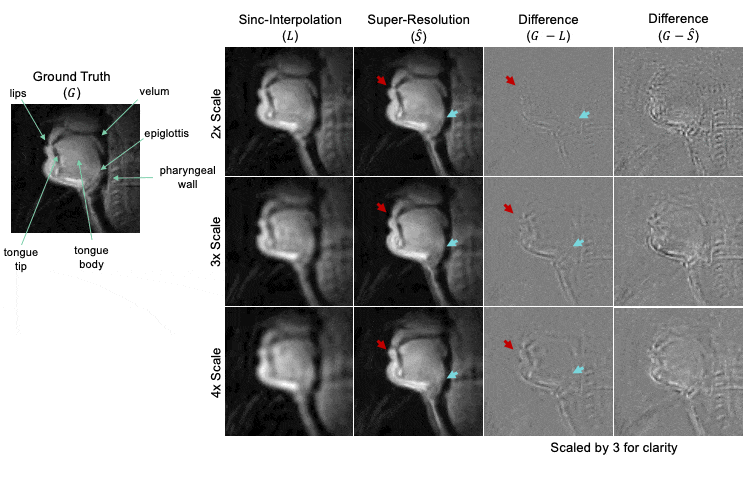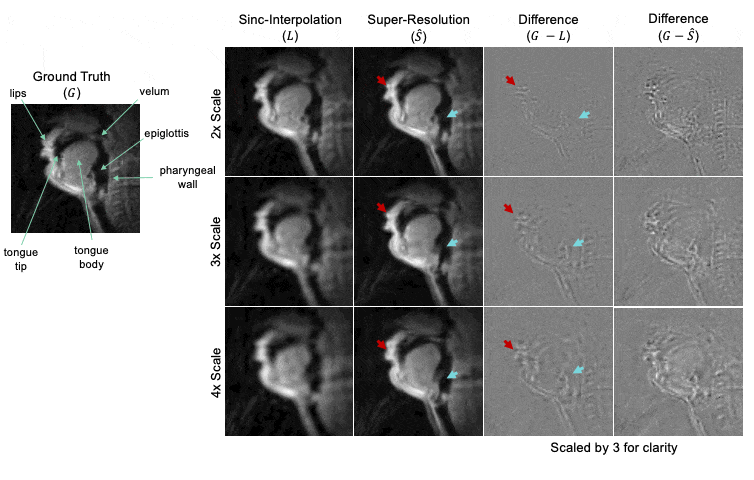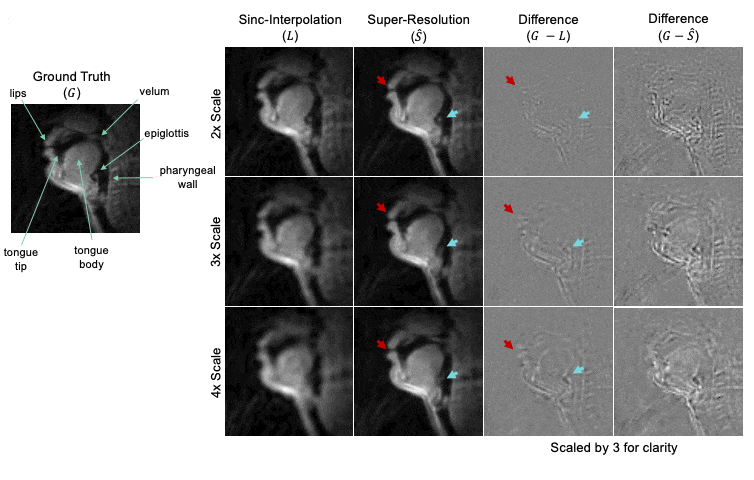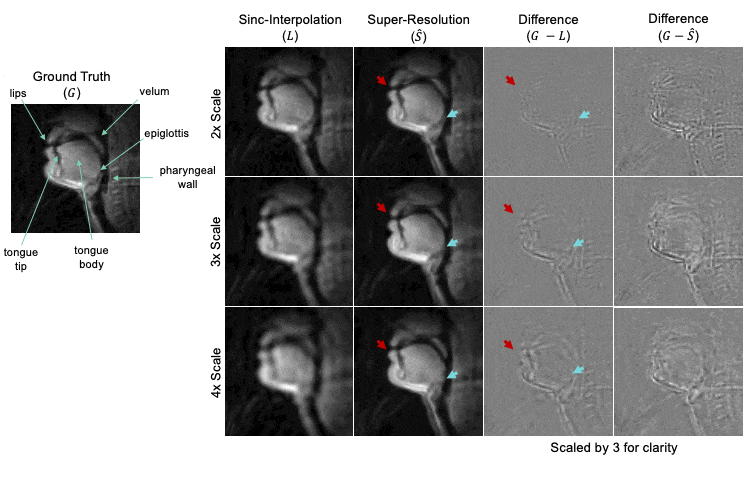
Figure 4: Representative example of DL network performance. The ground truth movie is labeled with relevant articulators. For each downsampling scale (2x, 3x, and 4x), we show the result of sinc-interpolation (1st column), super-resolution (2nd column), and difference images (3rd and 4th columns) with respect to ground truth. Lip boundaries appear blurred in the super-resolution estimate compared to the ground truth (red arrow). The epiglottis is successfully reconstructed in 2x case but lost/blurred in the 4x case (teal arrow).
