1Department of Experimental Physics 5, University of Würzburg, Würzburg, Germany, 2Department of Internal Medicine I, University Hospital Würzburg, Würzburg, Germany, 3Magnetic Resonance and X-Ray Imaging Department, Development Center X-ray Technology EZRT, Fraunhofer Institute for Integrated Circuits IIS, Würzburg, Germany
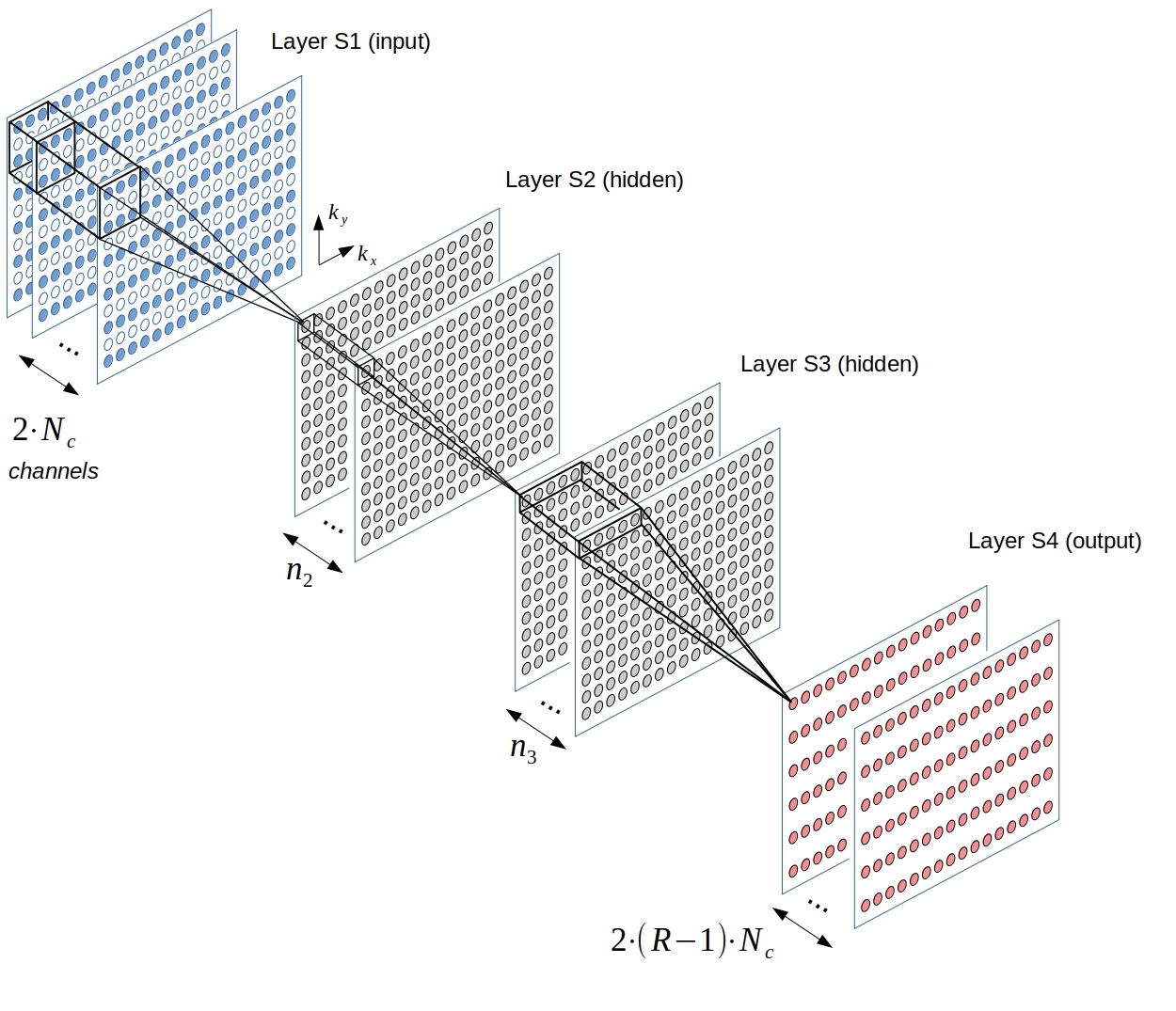
Fig. 1: The CNN architecture used in this work. The input layer takes in the subsampled, zerofilled k-space data of the coil array with Nc independent choils. Real- and imaginary part of the k-space data are passed to separate channels, resulting in 2 x Nc input-channels. Two hidden layers are assigned 256 and 128 channels, respectively (n2=256 and n3=128). The output layer predicts all missing points across all coils simultaneously, and thus has 2 x (R-1) x Nc channels, with R denoting the undersampling rate.

Fig. 2: 2D image reconstructions of brain dataset (32 coils, T1-weighted) for retrospective undersampling rates in range 4-6 (denoted as R4-R6). ACS data (30 central phase lines) were re-inserted into reconstructed k-spaces. GRAPPA kernel size was optimized for each undersampling rate: 11 x 4 (R4-5), and 15 x 2 (R6) in read- and phase direction. RAKI performs better than GRAPPA in terms of noise resilience, but suffers from blurring artifacts, which have pronounced appearance at 6-fold undersampling.
