Wenli Li1, Ziyu Meng1, Ruihao Liu1, Zhi-Pei Liang2,3, and Yao Li1
1School of Biomedical Engineering, Shanghai Jiao Tong University, Shanghai, China, 2Beckman Institute for Advanced Science and Technology, University of Illinois at Urbana-Champaign, Urbana, IL, United States, 3Department of Electrical and Computer Engineering, University of Illinois at Urbana-Champaign, Urbana, IL, United States
1School of Biomedical Engineering, Shanghai Jiao Tong University, Shanghai, China, 2Beckman Institute for Advanced Science and Technology, University of Illinois at Urbana-Champaign, Urbana, IL, United States, 3Department of Electrical and Computer Engineering, University of Illinois at Urbana-Champaign, Urbana, IL, United States
This paper presents a new method for multimodal
image fusion by integrating tensor modeling and deep learning. The proposed
method may prove useful for solving a range of multimodal brain image
processing problems.

Figure 1: Illustration of the proposed multimodal
fusion framework. The middle panel shows the tensor model-based joint
spatial-modality-intensity distribution and spatial prior representations. The bottom
panel shows the structure of the fusion network integrating the outputs from
different classifiers and spatial atlases.
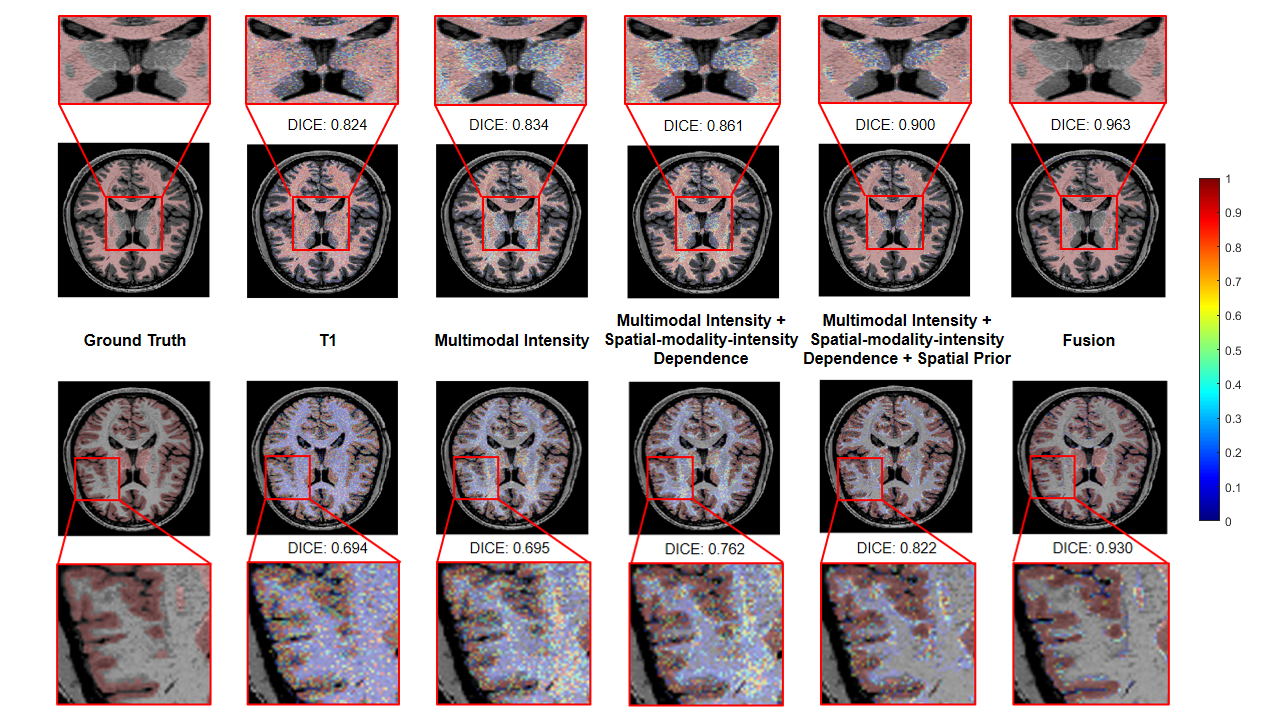
Figure 2: The performance comparison by
adding in each component in the proposed fusion framework. The segmentation
accuracy was improved with more features being added, which confirms the
advantage of capturing intensity-modality-spatial dependence information