SUBIN ERATTAKULANGARA1, KARTHIKA KELAT2, JUNJIE LIU3, and SAJAN GOUD LINGALA1,4
1Roy J Carver Department of Biomedical Engineering, University of Iowa, Iowa City, IA, United States, 2Government Engineering College Kozhikode, Kozhikode, India, 3Department of Neurology, University of Iowa, Iowa City, IA, United States, 4Department of Radiology, University of Iowa, Iowa City, IA, United States
1Roy J Carver Department of Biomedical Engineering, University of Iowa, Iowa City, IA, United States, 2Government Engineering College Kozhikode, Kozhikode, India, 3Department of Neurology, University of Iowa, Iowa City, IA, United States, 4Department of Radiology, University of Iowa, Iowa City, IA, United States
We propose a stacked hybrid learning U-NET architecture that automatically segments the tongue, velum, and airway in speech MRI. The segmentation accuracy of our stacked U-NET is comparable to a manual annotator. Also, the model can segment images at a speed of 0.21s/ image.
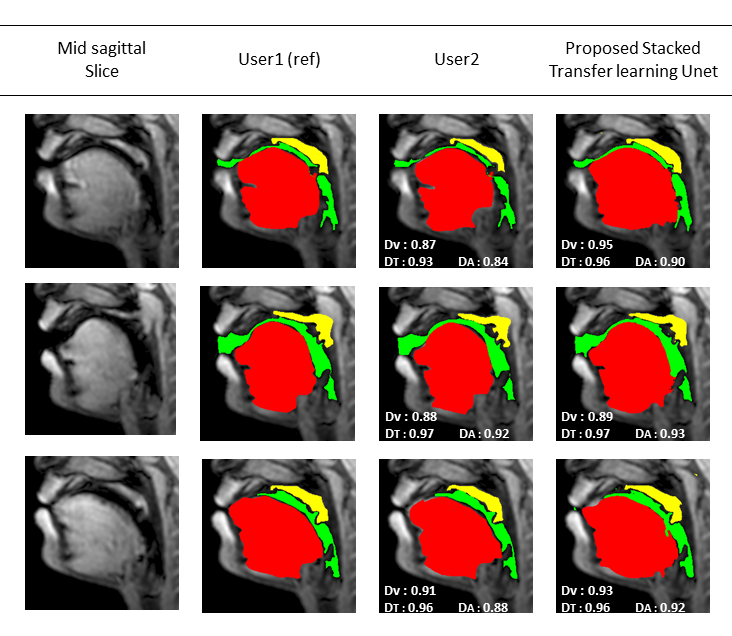
Figure 2: Results of multiple
articulator segmentation on the test data. Three sample postures are shown in
the figure. Reference segmentation from User1 is compared against segmentation
from User2 and the proposed stacked transfer learned based U-NET. The DICE
similarities for the tongue (T), airway (A), and the velum (V) are embedded.
These segmentations demonstrate good quality from the proposed U-NET scheme
with variability in the range of differences between user1-user2 segmentations.

Figure1: Stacked U-net architecture with hybrid learning. Each of the red boxes represents the U-NET model. The U-NET models for the tongue and velum segmentation are pre-trained with an open-source brain MRI dataset [6], and the UNET model for the airway is trained with an In-house airway MRI dataset. Later the velum and tongue U-nets are trained with an in-house MRI dataset which has few manually labeled (~60 images) articulator segmentations. The final output airway, tongue, velum, segmentation is the concatenated segmentations from the individual U-NET outputs.