Julie Camille DiCarlo1,2, Anum S Kazerouni3, and Thomas E Yankeelov1,2,4,5,6
1Oden Institute for Computational Engineering and Sciences, The University of Texas at Austin, Austin, TX, United States, 2Livestrong Cancer Institutes, The University of Texas at Austin, Austin, TX, United States, 3Department of Radiology, University of Washington, Seattle, WA, United States, 4Department of Biomedical Engineering, The University of Texas at Austin, Austin, TX, United States, 5Department of Diagnostic Medicine, The University of Texas at Austin, Austin, TX, United States, 6Department of Oncology, The University of Texas at Austin, Austin, TX, United States
1Oden Institute for Computational Engineering and Sciences, The University of Texas at Austin, Austin, TX, United States, 2Livestrong Cancer Institutes, The University of Texas at Austin, Austin, TX, United States, 3Department of Radiology, University of Washington, Seattle, WA, United States, 4Department of Biomedical Engineering, The University of Texas at Austin, Austin, TX, United States, 5Department of Diagnostic Medicine, The University of Texas at Austin, Austin, TX, United States, 6Department of Oncology, The University of Texas at Austin, Austin, TX, United States
Quantitative DCE-MRI fits parameters to
contrast agent concentration using the SPGR signal equation, T1
values, and contrast agent relaxivity. By simulating noise with ideal parameter
curves, we show why it’s better to fit to signal intensity rather than concentration
or relaxivity.
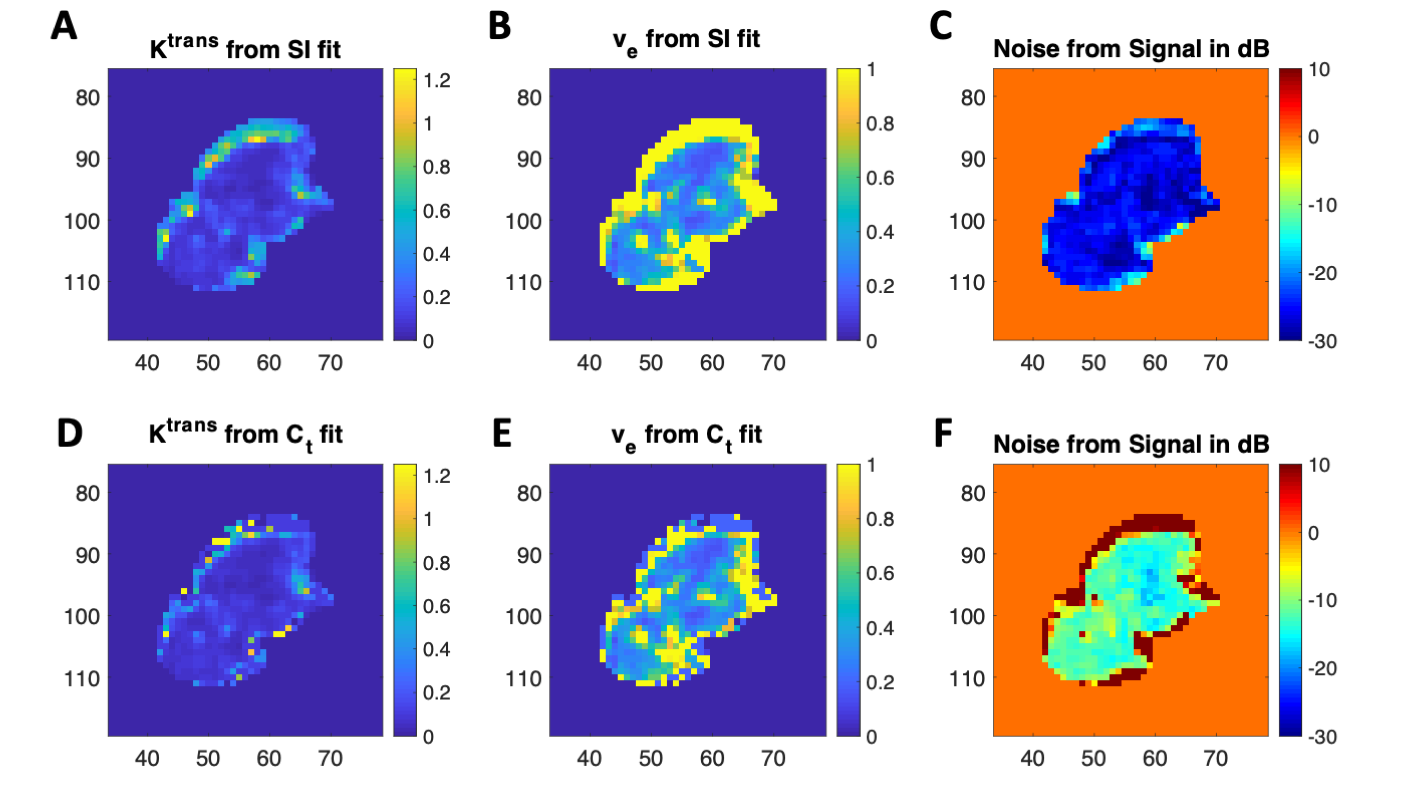
Figure 2. Example of Kety-Tofts standard model
parameter maps in a single slice of a breast cancer DCE-MRI exam, zoomed to the
tumor region of interest (ROI). (A) and
(D) Ktrans maps from fits to the signal intensity and
concentration, respectively. (B) and (E)
ve maps from fits to the signal intensity and concentration,
respectively. (C) and (F) Maps of the
estimated noise from each curve in dB (larger values represent noisier
fits.)
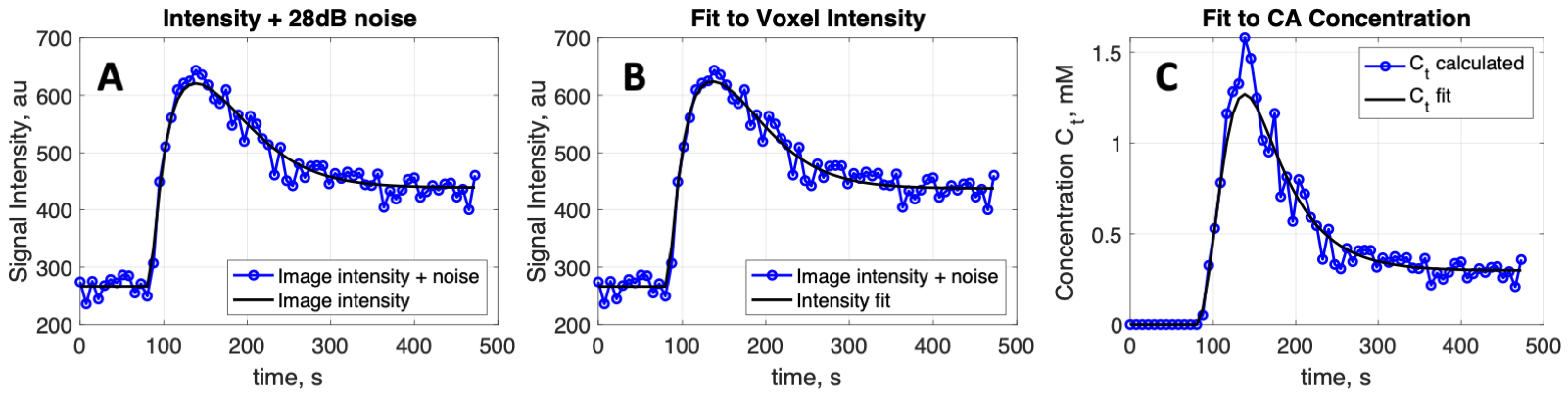
Figure 1. (A) Example of a simulated image
intensity curve with added Gaussian noise from the repeat Ktrans,
ve curve fits (N=1000 for each parameter pair and noise level.) (B) Same noise-added samples as (A) in blue,
but now black line is fit to the signal intensity curve. (C) Blue circles are
calculated contrast-agent concentration computed from the signal intensity
samples in (A) and (B), and the black line is fit to concentration samples. In
this instance of added noise, the concentration fit resulted in a Ktrans with 20% error,
while the intensity fit resulted in a Ktrans with a 10% error.